
State의 목적과 의미
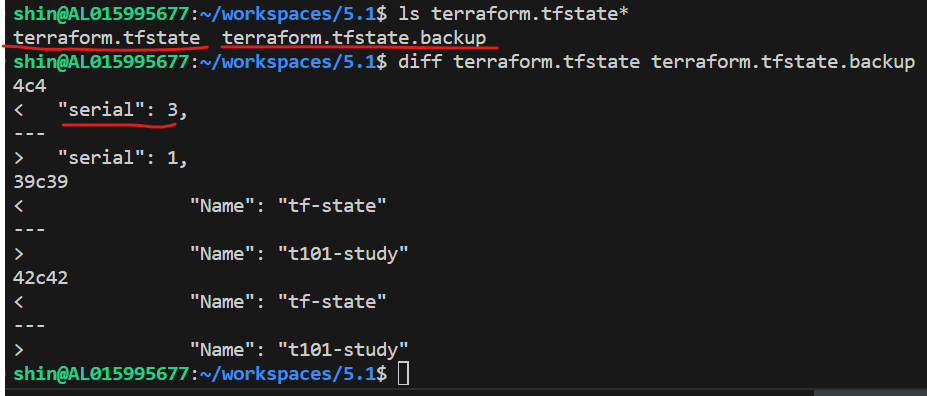
Serial을 기준으로 State backup 관리하는 것을 확인
vpc.tf
provider "aws" {
region = "ap-northeast-2"
}
resource "aws_vpc" "myvpc" {
cidr_block = "10.10.0.0/16"
tags = {
Name = "t101-study"
}
}terraform init && terraform plan && terraform apply -auto-approve
배포 이후
terraform.tfstate 파일이 생성 된 것을 확인 할 수 있다.

태그 수정 후 상태 파일을 확인해 보자!

백업 파일이 생성 되었고,
terraform.tfstate, terraform.tfstate.backup
현재 tfstate 파일은 시리얼 값이 3이 된 것을 알수 있다.
(Serial이 왜 2개가 증가하여 3이 되었는지 정확하게 모르겠다.)
팀단위 테라폼 운영 시 문제점
- 동일한 테라폼 상태 파일 사용을 위한 공유 위치에 저장
- 잠금 기능 없이 업데이트시 충돌 가능 (경쟁 상태 race condition)
- 상태 파일 격리 Isolating state files
- 예를 들면 테스트 dev 와 검증 stage 과 상용 prodction 각 환경에 대한 격리가 필요
상태 파일 공유로 버전 관리 시스템 비추천
- 수동 오류 Manual error (휴먼 에러)
- 테라폼을 실행하기 전에 최신 변경 사항을 가져오거나 실행하고 나서 push 하는 것을 잊기 쉽습니다(?).
- 팀의 누군가가 이전 버전의 상태 파일로 테라폼을 실행하고, 그 결과 실수로 이전 버전으로 롤백하거나 이전에 배포된 인프라를 복제하는 문제가 발생 할 수 있음.
- 수동 오류 해결 :
- plan/apply 실행 시 마다 해당 백엔드에서 파일을 자동을 로드, apply 후 상태 파일을 백엔드에 자동 저장
- 잠금 Locking (작업 충돌)
- 대부분의 버전 관리 시스템(VCS)은 여러 명의 팀 구성원이 동시에 하나의 상태 파일에 terraform apply 명령을 실행하지 못하게 하는 잠금 기능이 제공되지 않음.
- 잠금 해결
- apply 실행 시 테라폼은 자동으로 잠금을 활성화, -lock-timout=
- 시크릿 Secrets (민감 정보 노출)
- 테라폼 상태 파일의 모든 데이터는 평문으로 저장됨. 민감 정보가 노출될 위험.
- 시크릿 해결
- 대부분 원격 백엔드는 기본적으로 데이터를 보내거나 상태 파일을 저장할 때 암호화(Encryption)하는 기능을 지원
원격 백엔드는 AWS S3 를 의미한다.
수동오류를 방지하기 위해 apply 후 상태파일을 백엔드에 자동 저장하고,
작업간 충돌을 막기위해 Lock 기능을 구현해야 한다.
tfstate파일의 시크릿은 S3에서 지원한다.
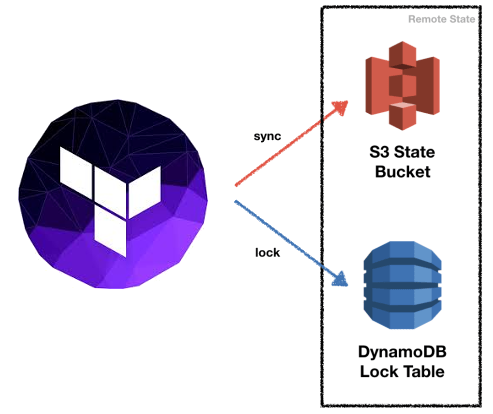
tfstate 파일 손실시 복구할 수 있는 방법은 없다.
관리를 잘해야 한다.
s3 버전관리 활성화
import로 한땀한땀 복구는 할수 있다.
프로바이더마다 import의 기능은 다를 수 있다.
Satate에 저장된 Sensitive 값 확인을 해보자
랜덤 패스워드 16자리 만드는 리소스이다.
resource "random_password" "mypw" {
length = 16
special = true
override_special = "!#$%"
}terraform init && terraform plan && terraform apply -auto-approve
배포 이후
민감한 정보임으로 sensitive로 가려 졌다.
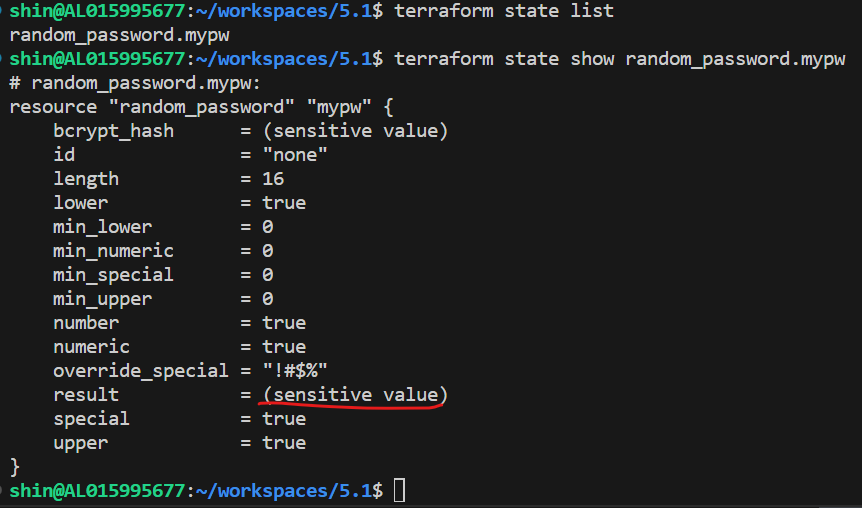
하지만
tfstate 파일안에서는 평문으로 저장 되어 있다.

State 동기화
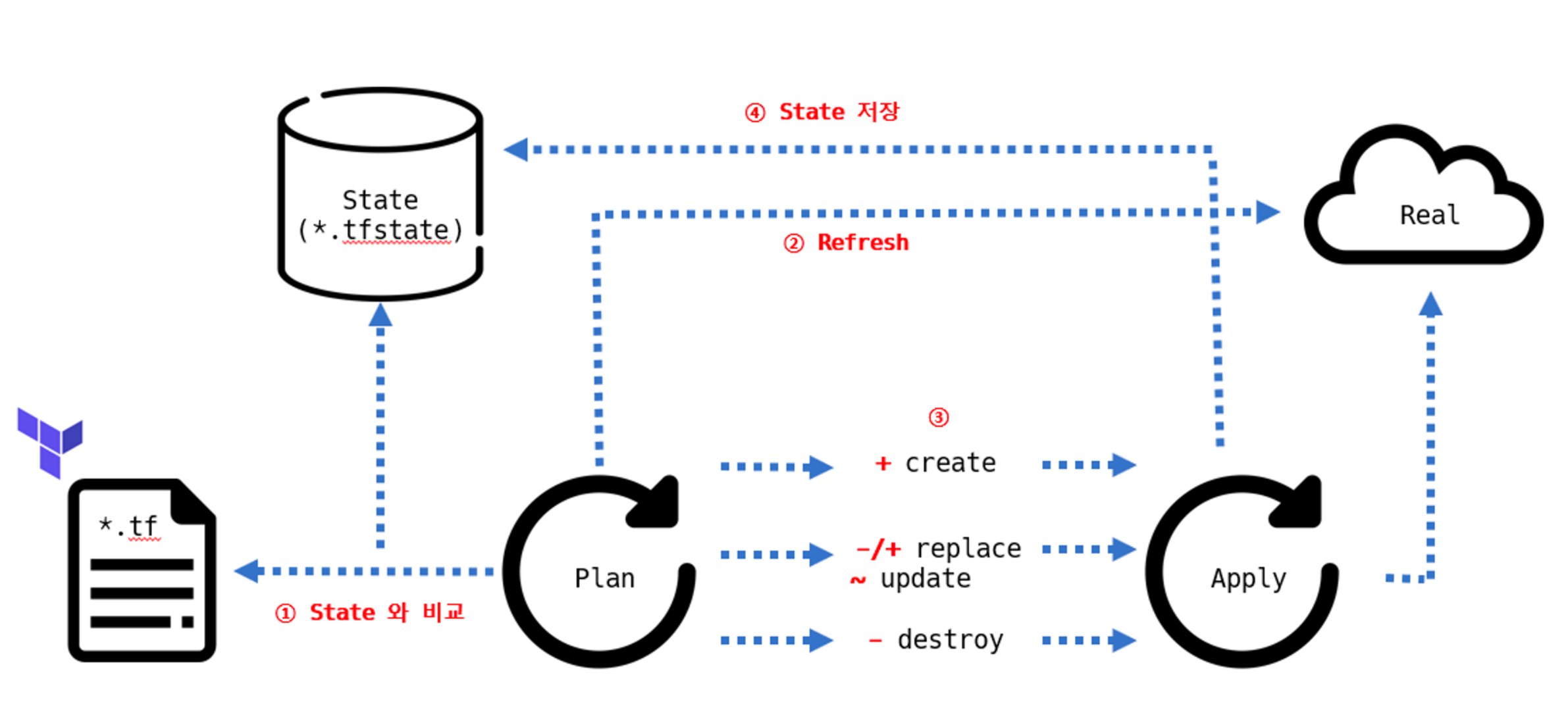
refresh false는 2번 과정을 생략 할 수 있다.
Plan을 하게 되면, 기본값으로 refresh 동작을 수행하면서,
리소스 생성 대상(클라우드 등)과 State를 기준으로 비교하는 과정을 거친다.
이 과정에서 State 리소스 양에 따라 속도 차이가 발생한다.
이를 실행해 빠르게 배포하고, 동기화 과정을 생략할때 사용할 수 있다.
# 실행 계획 생성 시 저장되어 있는 State와 실제 형상을 비교하는 기본 실행
time terraform plan
# 실행 계획 생성 시 실제 형상과 비교하지 않고 실행 계획을 생성하는 -refresh=false 옵션
time terraform plan -refresh=falseReplace 동작은 기본값은 "삭제 -> 생성"
lifecycle의 create_before_destroy 옵션을활용
생성 -> 삭제 가능
유형1 - 새로운 리소스 생성
(테라폼으로 클라우드 서비스 처음 생성하는 경우)
유형2 - 새로운 리소스 생성
(클라우드 서비스는 없는데, 클라우드 서비스를 이관 받는 경우)
유형3 - 동작 없음
유형4 - 운영 중인 리소스 삭제 됨
(테라폼 코드가 없기때문에)
유형5 - 동작 없음
(테라폼 없이 클라우드 서비스 운영중인 경우, import 작업으로 테라폼 도입)
유형6 - tfstate 파일이 삭제되어 있어서, *.tf 코드를 확인하고 tfstate가 새로 생성됨
(import 작업이 필요함)
(실수로 tfstate파일을 삭제해버린 경우)

워크스페이스 (작업 공간을 만드는 팁)
- 작업 공간을 통한 격리 Isolation via workspaces
- 동일한 구성에서 빠르고 격리된 테스트 환경에 유용
- 논리적 격리 가능
- 파일 레이아웃을 이용한 격리 Isolation via file layout
- 보다 강력하게 분리해야 하는 운영 환경에 적합
- 테라폼 프로젝트의 파일 레이아웃 설명
- 각 테라폼 구성 파일을 분리된 폴더에 넣기. (예. stage , prod)
- 각 환경에 서로 다른 백엔드 구성. (예. S3 버킷 백엔드의 AWS 계정을 분리)
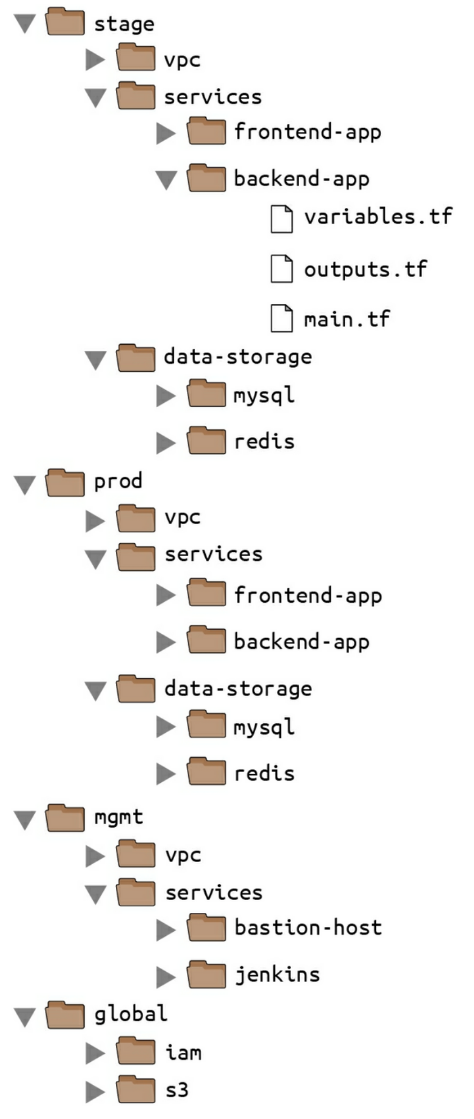
최상위 폴더
- stage : 테스트 환경과 같은 사전 프로덕션 워크로드 workload 환경
- prod : 사용자용 맵 같은 프로덕션 워크로드 환경
- mgmt : 베스천 호스트 Bastion Host, 젠킨스 Jenkins 와 같은 데브옵스 도구 환경
- global : S3, IAM과 같이 모든 환경에서 사용되는 리소스를 배치
각 환경별 구성 요소
- vpc : 해당 환경을 위한 네트워크 토폴로지
- services : 해당 환경에서 서비스되는 애플리케이션, 각 앱은 자체 폴더에 위치하여 다른 앱과 분리
- data-storage : 해당 환경 별 데이터 저장소. 각 데이터 저장소 역시 자체 폴더에 위치하여 다른 데이터 저장소와 분리
명명 규칙 naming conventions (예시)
- variables.tf : 입력 변수
- outputs.tf : 출력 변수
- main-xxx.tf : 리소스 → 개별 테라폼 파일 규모가 커지면 특정 기능을 기준으로 별도 파일로 분리 (ex. main-iam.tf, main-s3.tf 등) 혹은 모듈 단위로 나눔 → 리소스 명으로 구분해서 작성하는 방법도 있습니다.
- dependencies.tf : 데이터 소스
- providers.tf : 공급자
워크스페이스를 이용하여 어떻게 관리할 수 있는지 알아보자
기본적으로 테라폼은 워크스페이스를 사용하고 있다.
terraform workspace list

새로운 워크스페이스를 생성해서 배포해보자
terraform workspace new mywork1
terraform apply -auto-approve
terraform.tfstate.d 밑에 새로운 폴더가 생성되고,
새로운 tfstate 가 생성되어 논리적으로 분리가 되었다.
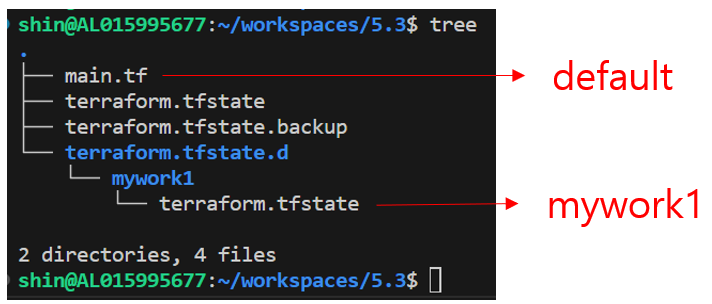
- 장점
- 하나의 루트 모듈에서 다른 환경을 위한 리소스를 동일한 테라폼 구성으로 프로비저닝하고 관리
- 기존 프로비저닝된 환경에 영향을 주지 않고 변경 사항 실험 가능
- 깃의 브랜치 전략처럼 동일한 구성에서 서로 다른 리소스 결과 관리
- 단점
- State가 동일한 저장소(로컬 또는 백엔드)에 저장되어 State 접근 권한 관리가 불가능(어려움)
- 모든 환경이 동일한 리소스를 요구하지 않을 수 있으므로 테라폼 구성에 분기 처리가 다수 발생 가능
- 프로비저닝 대상에 대한 인증 요소를 완벽히 분리하기 어려움⇒ 해결방안 1. 해결하기 위해 루트 모듈을 별도로 구성하는 디렉터리 기반의 레이아웃을 사용할 수 있다. ⇒ 해결방안 2. Terraform Cloud 환경의 워크스페이스를 활용
- → 가장 큰 단점은 완벽한 격리가 불가능
Module
- 테라폼으로 인프라와 서비스를 관리하면 시간이 지날수록 구성이 복잡해지고 관리하는 리소스가 늘어나게 된다. 테라폼의 구성 파일과 디렉터리 구성에는 제약이 없기 때문에 단일 파일 구조상에서 지속적으로 업데이트할 수 있지만, 다음과 같은 문제가 발생한다.
- 테라폼 구성에서 원하는 항목을 찾고 수정하는 것이 점점 어려워짐
- 리소스들 간의 연관 관계가 복잡해 질수록 변경 작업의 영향도를 분석하기 위한 노력이 늘어남
- 개발/스테이징/프로덕션 환경으로 구분된 경우 비슷한 형태의 구성이 반복되어 업무 효율이 줄어듦
- 새로운 프로젝트를 구성하는 경우 기존 구성에서 취해야 할 리소스 구성과 종속성 파악이 어려움
- 모듈은 테라폼 구성의 집합이다. 테라폼으로 관리하는 대상의 규모가 커지고 복잡해져 생긴 문제를 보완하고 관리 작업을 수월하게 하기 위한 방안으로 활용
- 관리성 : 모듈은 서로 연관 있은 구성의 묶음이다. 원하는 구성요소를 단위별로 쉽게 찾고 업데이트할 수 있다. 모듈은 다른 구성에서 쉽게 하나의 덩어리로 추가하거나 삭제할 수 있다. 또한 모듈이 업데이트되면 이 모듈을 사용하는 모든 구성에서 일관된 변경 작업을 진행할 수 있다.
- 캡슐화 : 테라폼 구성 내에서 각 모듈은 논리적으로 묶여져 독립적으로 프로비저닝 및 관리되며, 그 결과는 은닉성을 갖춰 필요한 항목만을 외부에 노출시킨다.
- 재사용성 : 구성을 처음부터 작성하는 것에는 시간과 노력이 필요하고 작성 중간에 디버깅과 오류를 수정하는 반복 작업이 발생한다. 테라폼 구성을 모듈화하면 이후에 비슷한 프로비저닝에 이미 검증된 구성을 바로 사용할 수 있다.
- 일관성과 표준화 : 테라폼 구성 시 모듈을 활용하는 워크플로는 구성의 일관성을 제공하고 서로 다른 환경과 프로젝트에도 이미 검증한 모듈을 적용해 복잡한 구성과 보안 사고를 방지할 수 있다.
- 기본 원칙 : 모듈은 대부분의 프로그래밍 언어에서 쓰이는 라이브러리나 패키지와 역할이 비슷하다
- 모듈 디렉터리 형식을 terraform-<프로바이더 이름>-<모듈 이름> 형식을 제안한다. 이 형식은 Terraform Cloud, Terraform Enterprise에서도 사용되는 방식으로
- 1) 디렉터리 또는 레지스트리 이름이 테라폼을 위한 것이고,
- 2) 어떤 프로바이더의 리소스를 포함하고 있으며,
- 3) 부여된 이름이 무엇인지 판별할 수 있도록 한다.
- 테라폼 구성은 궁극적으로 모듈화가 가능한 구조로 작성할 것을 제안한다. 처음부터 모듈화를 가정하고 구성파일을 작성하면 단일 루트 모듈이라도 후에 다른 모듈이 호출할 것을 예상하고 구조화할 수 있다. 또한 작성자는 의도한 리소스 묶음을 구상한 대로 논리적인 구조로 그룹화할 수 있다.
- 각각의 모듈을 독립적으로 관리하기를 제안한다. 리모트 모듈을 사용하지 않더라도 처음부터 모듈화가 진행된 구성들은 때로 루트 모듈의 하위 파일 시스템에 존재하는 경우가 있다. 하위 모듈 또한 독립적인 모듈이므로 루트 모듈 하위에 두기보다는 동일한 파일 시스템 레벨에 위치하거나 별도 모듈만을 위한 공간에서 불러오는 것을 권장한다. 이렇게 하면 VCS를 통해 관리하기가 더 수월하다.
- 공개된 테라폼 레지스트리의 모듈을 참고 하기를 제안한다. 대다수의 테라폼 모듈은 공개된 모듈이 존재하고 거의 모든 인수에 대한 변수 처리, 반복문 적용 리소스, 조건에 따른 리소스 활성/비활성 등을 모범 사례로 공개해두었다. 물론 그대로 가져다 사용하는 것보다는 프로비저닝하려는 상황에 맞게 참고하는 것을 권장한다.
- 작성된 모듈은 공개 또는 비공개로 게시해 팀 또는 커뮤니티와 공유하기를 제안한다. 모듈의 사용성을 높이고 피드백을 통해 더 발전된 모듈을 구성할 수 있는 자극이 된다.
- 모듈 디렉터리 형식을 terraform-<프로바이더 이름>-<모듈 이름> 형식을 제안한다. 이 형식은 Terraform Cloud, Terraform Enterprise에서도 사용되는 방식으로

자식 모듈을 작성
# main.tf
resource "random_pet" "name" {
keepers = {
ami_id = timestamp()
}
}
# DB일 경우 Password 생성 규칙을 다르게 반영
resource "random_password" "password" {
length = var.isDB ? 16 : 10
special = var.isDB ? true : false
override_special = "!#$%*?"
}# variable.tf
variable "isDB" {
type = bool
default = false
description = "패스워드 대상의 DB 여부"
}# output.tf
output "id" {
value = random_pet.name.id
}
output "pw" {
value = nonsensitive(random_password.password.result)
}그래프를 보면
root 모듈 하위에 생긴 구조로 보인다.
모듈화 되어 있지 않은 구조이다.

자식 모듈 호출
module "mypw1" {
source = "../modules/terraform-random-pwgen"
}
module "mypw2" {
source = "../modules/terraform-random-pwgen"
isDB = true
}
output "mypw1" {
value = module.mypw1
}
output "mypw2" {
value = module.mypw2
}모듈 형태로 만들어 있는 것이 확인 된다.

modules.json이 생성 된 것이 확인 된다.


유형 1. 자식 모듈에서 프로바이더 정의
- 모듈에서 사용하는 프로바이더 버전과 구성 상세를 자식 모듈에서 고정하는 방법이다.
- 프로바이더 버전과 구성에 민감하거나, 루트 모듈에서 프로바이더 정의 없이 자식 모듈이 독립적인 구조일 때 고려할 방법이다
- 하지만 동일한 프로바이더가 루트와 자식 양쪽에 또는 서로 다른 자식 모듈에 버전 조건 합의가 안 되면, 오류가 발생하고 모듈에 반복문을 사용할 수 없다는 단점이 있으므로 잘 사용하지 않는다.
유형 2. 루트 모듈에서 프로바이더 정의(실습)
- 자식 모듈은 루트 모듈의 프로바이더 구성에 종속되는 방식이다.
- 디렉터리 구조로는 분리되어 있지만 테라폼 실행 단계에서 동일 계층으로 해석되므로 프로바이더 버전과 구성은 루트 모듈의 설정이 적용된다. 프로바이더를 모듈 내 리소스와 데이터 소스에 일괄 적용하고, 자식 모듈에 대한 반복문 사용에 자유로운 것이 장점이다. 자식 모듈에 특정 프로바이더 구성의 종속성은 반영할 수 없으므로 자식 모듈을 프로바이더 조건에 대해 기록하고, 자식 모듈을 사용하는 루트 모듈에서 정의하는 프로바이더에 맞게 업데이트 해야 한다.
- 다음은 동일한 모듈에 사용되는 프로바이더 조건이 다른 경우 각 모듈별로 프로바이더를 맵핑하는 방안이다.
- 리소스와 데이터 소스에 provider 메타인수로 지정하는 방식과 비슷하나 모듈에는 다수의 프로바이더가 사용될 가능성이 있으므로 map 타입으로 구성하는 provider로 정의한다.
작성시 모듈 레지스트리를 참조하자
검증된 모듈구조
https://registry.terraform.io/browse/modules
느낀점
State의 중요함을 자세히 알아봤다.
serial이 저장되고, 백업되는 과정
state 파일의 운영시 문제점과 보완 방법
sensitive는 암호화가 안되고, tfstate에 평문으로 저장
워크스페이스 사용법
디렉토리 관리방법
명명규칙 등등
모듈에 대해서, 모듈 사용법, 조심할점, 꿀팁 등등
알수 있게 되어서 너무 감사하다.
[도전과제1] T101 1기 노션 내용에 AWS DynamoDB/S3를 원격 저장소로 사용하는 실습을 따라해보세요!
S3 리소스 먼저 생성
provider "aws" {
region = "ap-northeast-2"
}
resource "aws_s3_bucket" "mys3bucket" {
bucket = "thumbup-t101study-tfstate"
}
# Enable versioning so you can see the full revision history of your state files
resource "aws_s3_bucket_versioning" "mys3bucket_versioning" {
bucket = aws_s3_bucket.mys3bucket.id
versioning_configuration {
status = "Enabled"
}
}
output "s3_bucket_arn" {
value = aws_s3_bucket.mys3bucket.arn
description = "The ARN of the S3 bucket"
}
S3를 버전 관리 활성화 상태로 생성해 준다.
terraform plan && terraform apply -auto-approve


dynamodb 테이블을 생성한다.
DynamoDB 잠금을 사용하기 위해서는 LockID 라는 기본 키가 있는 테이블을 생성
resource "aws_dynamodb_table" "mydynamodbtable" {
name = "terraform-locks"
billing_mode = "PAY_PER_REQUEST"
hash_key = "LockID"
attribute {
name = "LockID"
type = "S"
}
}
output "dynamodb_table_name" {
value = aws_dynamodb_table.mydynamodbtable.name
description = "The name of the DynamoDB table"
}
dynamodb 생성 확인

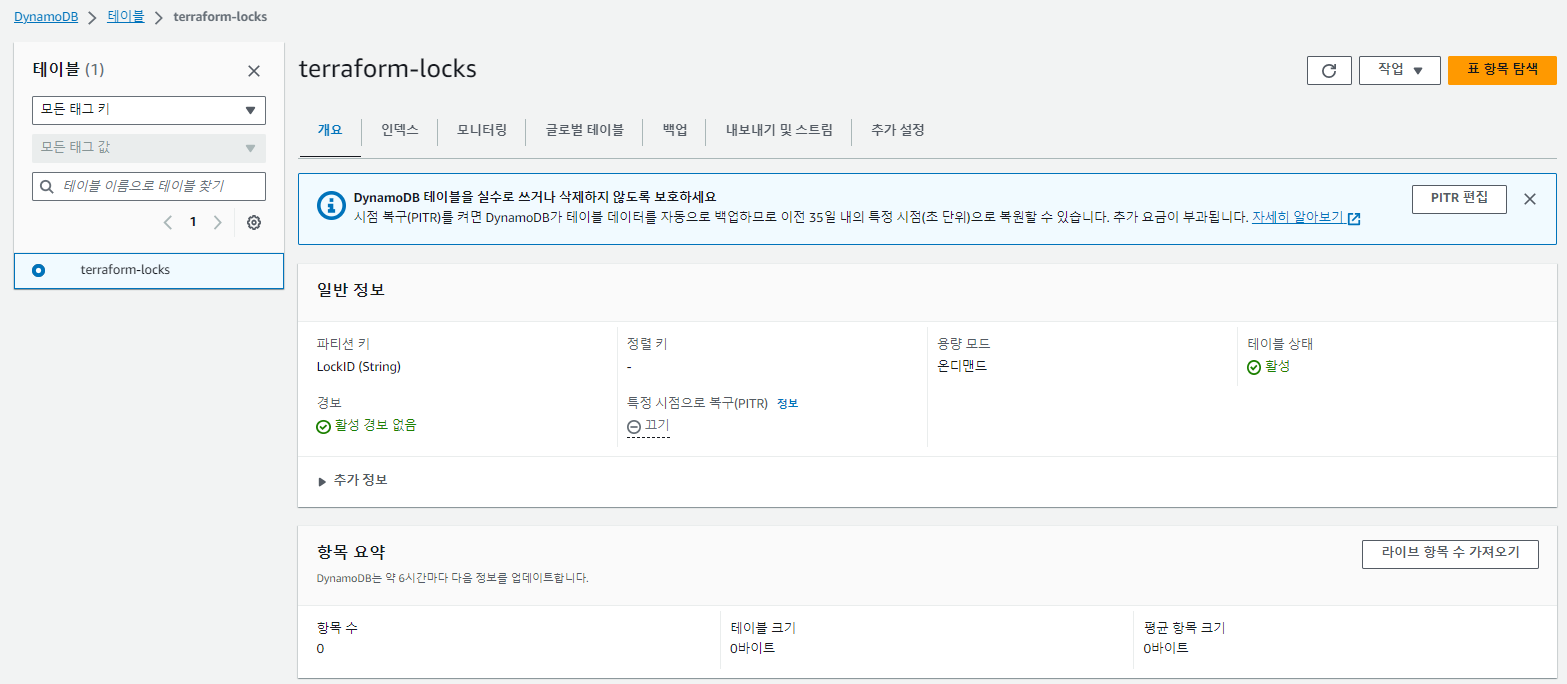
백엔드 적용 실습
리소스 생성후에, s3와 dynamodb 항목에 추가 된 것을 확인 했다.

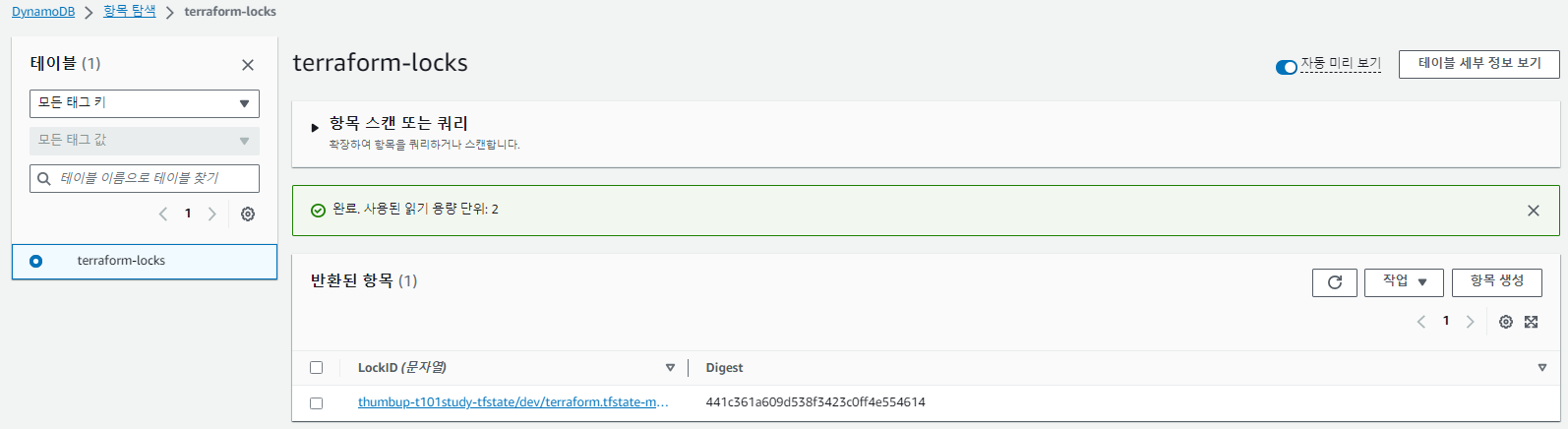
S3 버전 기능을 활성화 해서 확인 했다.

두개의 셀에서 동시에 실행해서 충돌을 발생 시켜 보자
# 왼쪽 쉘
sed -i -e 's/HallsHolicker-jjang/akbun-jjangg1/g' ec2.tf
terraform plan && terraform apply -lock-timeout=60s -auto-approve
# 오른쪽 쉘
sed -i -e 's/HallsHolicker-jjang/akbun-jjangg2/g' ec2.tf
terraform plan && terraform apply -lock-timeout=60s -auto-approve
오른쪽 쉘을 늦게 시작 했는데,
"Error acquiring the state lock 이 발생한 것을 알 수 있다.

느낀점
생각보다 backend를 쉽고 간단하게 구성이 가능하단 것을 알았다.
정리해준 내용만 보고 따라 하면 lock 기능도 쉽게 구현 가능하다!
감사하다!

'테라폼 > T101[3기]' 카테고리의 다른 글
| T101 - 5주차 / 02 (0) | 2023.10.07 |
|---|---|
| T101 - 5주차 / 01 (0) | 2023.10.06 |
| T101 - 3주차 (0) | 2023.09.16 |
| T101 - 2주차 (0) | 2023.09.09 |
| T101 - 1주차 (0) | 2023.09.02 |